 Skip to content
Skip to content 
Spark is a distributed computing framework that allows for processing large datasets in parallel across a cluster of computers. When running a Spark job, it is not uncommon to encounter failures due to various issues such as network or hardware failures, software bugs, or even insufficient memory. One way to address these issues is to re-run the entire job from the beginning, which can be time-consuming and inefficient. To mitigate this problem, Spark provides a mechanism called check-pointing.

Why do we even need a checkpoint?
Someone needs to remember what was done before or what was processed before, or what we know so far. All this information needs to be stored somewhere. The place where this is stored is called a Checkpoint.
How does checkpoint work?
Think of it as a 3 step process:
- Fetch the source metadata and write to Write Ahead Log (WAL)/Offsets
- Fetch the source data, process it, and write to sink
- Write state & commit information
Checkpoints store the current offsets and state values (e.g. aggregate values) for your stream. Checkpoints are stream specific, so each should be set to its own location.
This is an advanced blog and should be read with the expectation of familiarizing and not understanding. Read this and bookmark it; once you come across a situation where you need to dig into the checkpoint, this blog will come in handy.
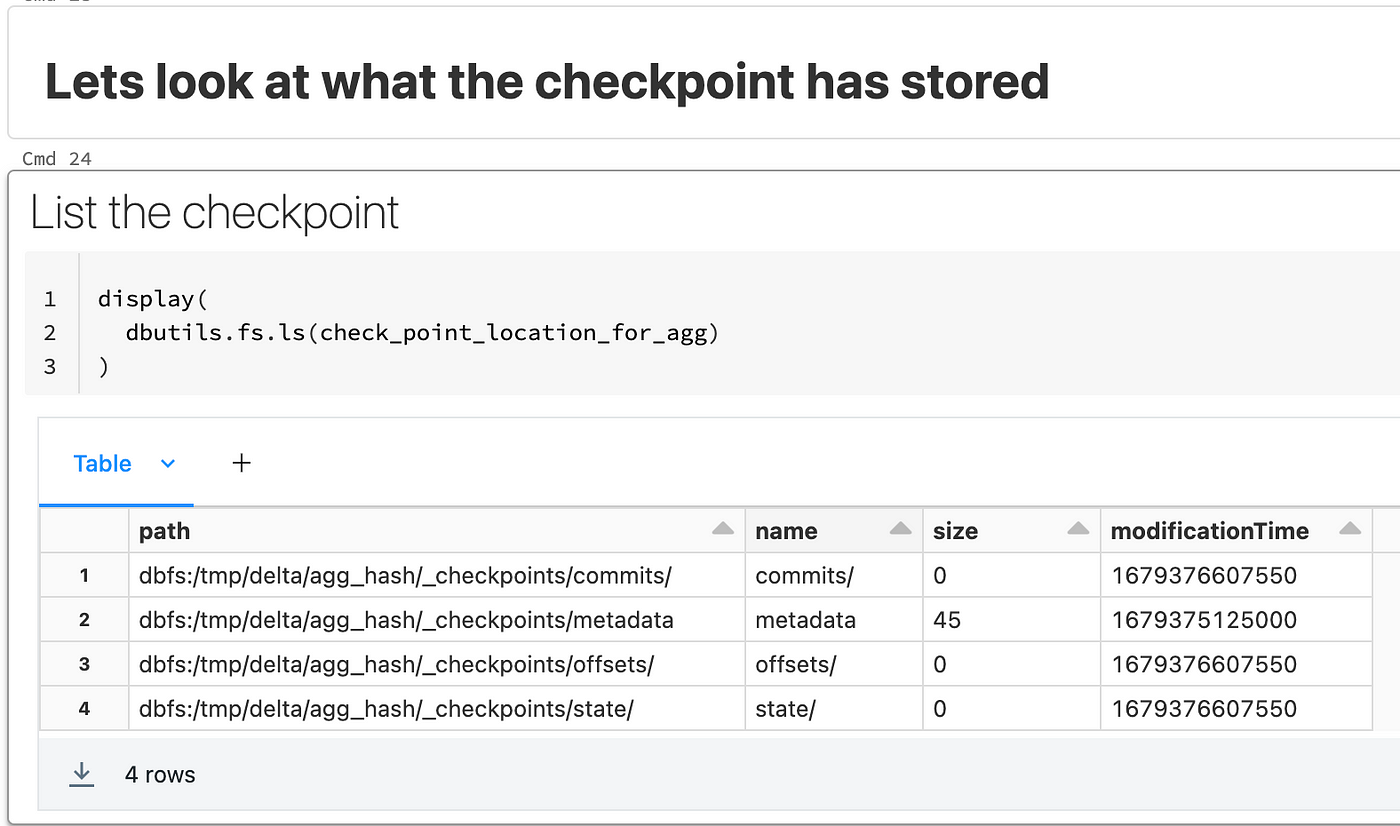
What is inside a checkpoint folder?
It will have 3 folders inside it and a metadata file:
- offsets: This contains the WAL information.
- commits: Once data is processed, the offset information will go inside it
- State: Only if stateful operations are involved.
- metadata: Metadata about the stream. This is a file
What is inside the Offsets file?
The easiest way to think about it is that once we start processing a micro-batch of data. We need to store an upper bound mark and a lower bound mark of the data. This mark could be called an offset. Think if you a measuring something with a scale and you need to log the reading. This reading, aka the offset, we will store in the offsets file.

Different sources like Kafka, Kinesis, Delta, etc., all have different ways of defining offsets, but conceptually they are the same.
For this blog, let’s concentrate on Delta as a streaming source.
- Reservoir ID (aka Table ID): This is your Delta Table id
- reservoirVersion is the version of the Delta table that the micro-batch(current stream execution) started with
- Index: File index of the current Delta Table version being processed. Every time you write to a Delta table, the Table version is incremented. As part of the write operation, multiple files are written. Within that Delta Table Version, the file number being processed is represented by the index.
- isStartingVersion: This is just true or false. It is true to denote a query starting rather than processing changes.

This stores the stream-id, which is generated when the stream starts and remains the same throughout the life of the checkpoint.

Commits
These files are generated only when the micro-batch succeeds. Offsets are generated at the start of the micro-batch. If the offset did not have a corresponding commit, a failure happened when processing that offset.
In an ideal scenario, the number of commit files equals the number of offset files. However, when they are not equal, the next Spark Streaming knows where to start because it’s stored in the offset file, which did not have a corresponding commit. Furthermore, watermarking information would be found here.

State Store
This folder only has data in the case of Stateful Streaming, where the State is stored on disk for resiliency purposes. Thus when failures happen, the state can be recovered from here.
- State is also stored as a Delta table
- _metadata will hold the schema of the state

References
Please spare some time to look at the below to help absorb the above content further.
- https://www.youtube.com/watch?v=1cBDGsSbwRA&t=442s
- https://www.databricks.com/blog/2022/12/12/streaming-production-collected-best-practices.html
Footnote:
Thank you for taking the time to read this article. If you found it helpful or enjoyable, please consider clapping to show appreciation and help others discover it. Don’t forget to follow me for more insightful content, and visit my website CanadianDataGuy.com for additional resources and information. Your support and feedback are essential to me, and I appreciate your engagement with my work.
