
Introduction
In today’s data landscape, organizations often deal with multiple input datasets from various sources like Kafka, Kinesis, and Delta tables. These datasets may have different schemas but sometime to be combined into a single, unified table. Delta Live Tables (DLT) in Databricks simplifies this process by handling schema evolution and managing Slowly Changing Dimensions (SCD) efficiently.
Why Delta Live Tables?
Delta Live Tables offers several benefits:
- Real-time Data Processing: Ensures data is processed and available in real-time.
- Schema Evolution: Automatically propagates new columns from source to target.
- SCD Type 1 and 2: Easily build SCD Type 1 and Type 2.
- Inserts, Updates, Deletes: Handles all data operations efficiently.

Use Case
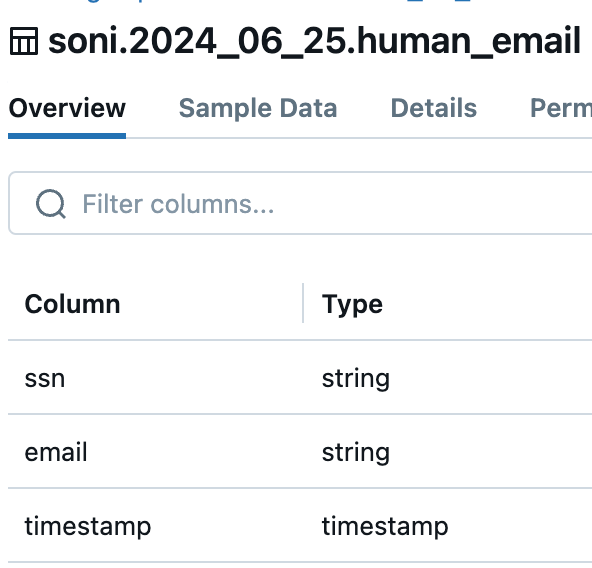
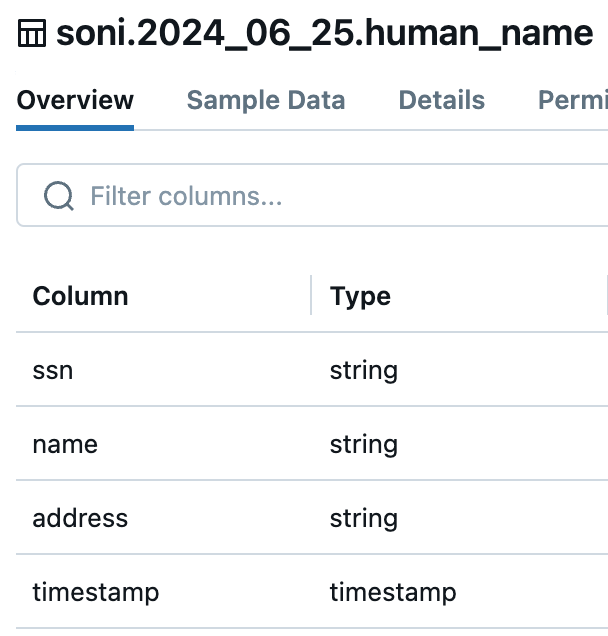
We aim to merge multiple data streams (human_name, human_email, and human_date_of_birth) into a single Delta table (DIM_SSN_SCD_TYP_2) using the common join key ssn. The input data can come from Kafka, Kinesis, or Delta, or a combination of these sources.
We have 3 datasets with different schemas and combine attributes of all of them into a single table.

The Solution: CHANGE FLOWs API
Delta Live Tables is currently previewing a CHANGE FLOWs API, which allows multiple APPLY CHANGES streams to write to a streaming table within a single pipeline. This functionality enables:
- Performing data backfills to existing
APPLY CHANGESstreaming table targets. - Ingesting data from multiple independent
APPLY CHANGESprocesses into the same target table. - Performing initial hydration (using
once=trueAPI) of a streaming table to support Change Data Capture (CDC) use cases.
The apply_changes method uses the existing APPLY CHANGE API with an additional once property to specify whether the operation should run only once.
apply_changes(
once=True, # optional, only run this code once; ignore new files added to this location
target="<existing-target-table>",
source="<data-source>",
keys=["key1", "key2", "keyN"], # must match <existing-target-table>
sequence_by="<sequence-column>", # must match <existing-target-table>
ignore_null_updates=False, # must match <existing-target-table>
apply_as_deletes=None,
apply_as_truncates=None,
column_list=None,
except_column_list=None,
stored_as_scd_type=<type>, # must match <existing-target-table>
track_history_column_list=None, # must match <existing-target-table>
track_history_except_column_list=None
)
Implementation
Imports and Parameters
Define the parameters for our catalog, database names, and the target table name.
import dlt
from pyspark.sql.functions import *
catalog_name = "soni"
database_name = "2024_06_25"
tables = ["human_name", "human_email", "human_date_of_birth"]
target_name = "DIM_SSN_SCD_TYP_2"
Creating DLT Views
Create DLT views for each source table dynamically.
for table in tables:
@dlt.view(name=f"dlt_view_{table}")
def create_view(table=table):
"""
Creates a DLT view for the given table from the Delta table.
Args:
table (str): Name of the table to create the view for.
Returns:
DataFrame: Streaming DataFrame containing the data from the specified table.
"""
table_path = f"{catalog_name}.`{database_name}`.{table}"
return spark.readStream.format("delta").table(table_path)
Creating the Streaming Target Table
Create a streaming target table to merge the data streams.
dlt.create_streaming_table(
name=target_name,
table_properties={
"pipelines.autoOptimize.zOrderCols": "ssn",
},
)
Note: The
pipelines.autoOptimize.zOrderColsproperty is set tossnbecause all merges are happening on thessncolumn, and clustering the table on this column optimizes the performance of these merge operations.
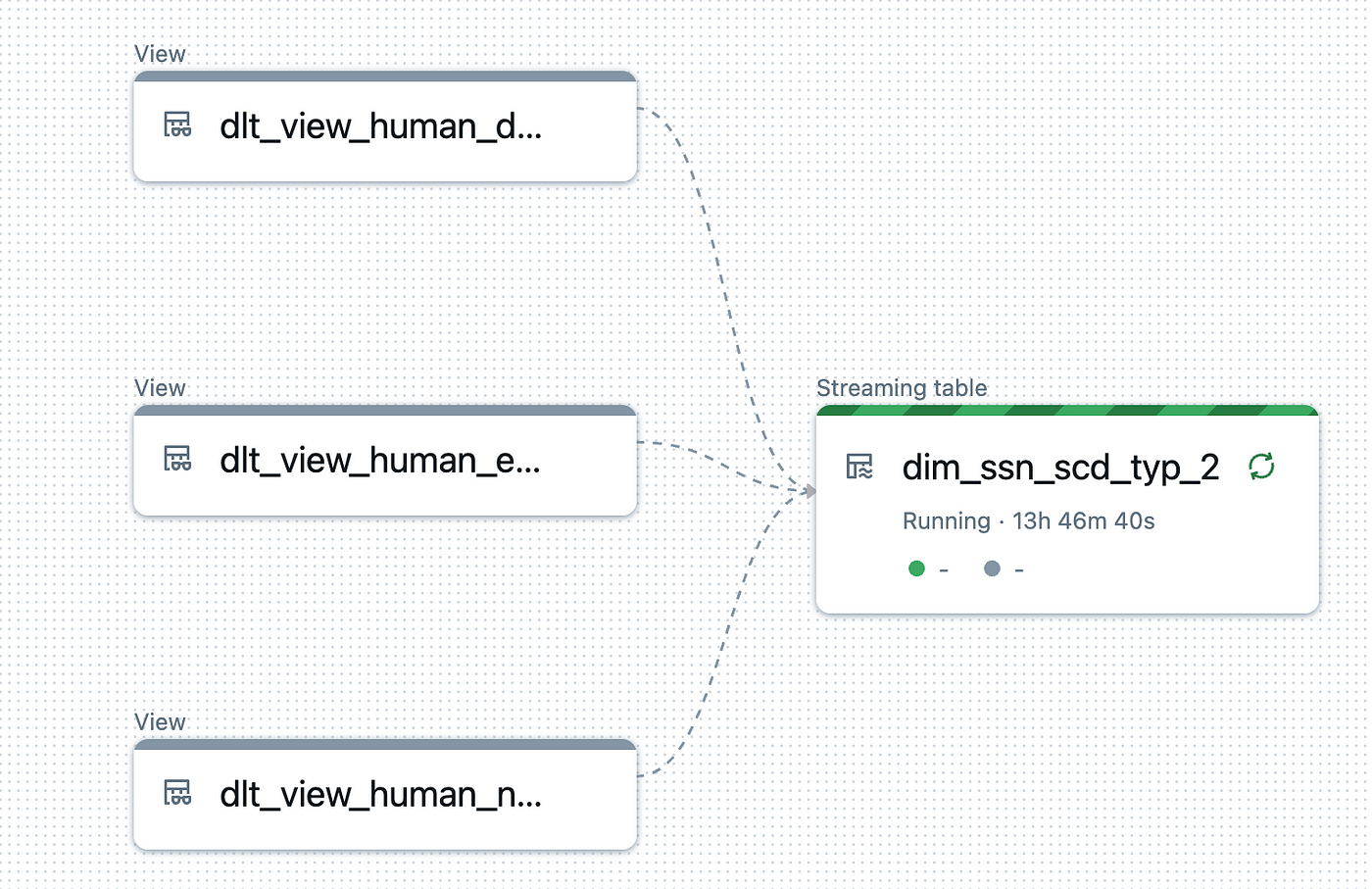
Merging Data Streams into the Delta Table
Merge each stream into the target table using apply_changes.
dlt.apply_changes(
flow_name=f"streaming_data_from_dlt_view_human_name_to_merge_into_{target_name}",
target=target_name,
source="dlt_view_human_name",
keys=["ssn"],
ignore_null_updates=True,
stored_as_scd_type="2",
sequence_by="timestamp",
)
dlt.apply_changes(
flow_name=f"streaming_data_from_dlt_view_human_email_to_merge_into_{target_name}",
target=target_name,
source="dlt_view_human_email",
keys=["ssn"],
ignore_null_updates=True,
stored_as_scd_type="2",
sequence_by="timestamp",
)
dlt.apply_changes(
flow_name=f"streaming_data_from_dlt_view_human_date_of_birth_to_merge_into_{target_name}",
target=target_name,
source="dlt_view_human_date_of_birth",
keys=["ssn"],
ignore_null_updates=True,
stored_as_scd_type="2",
sequence_by="timestamp",
)
Output table with SCD Type 2
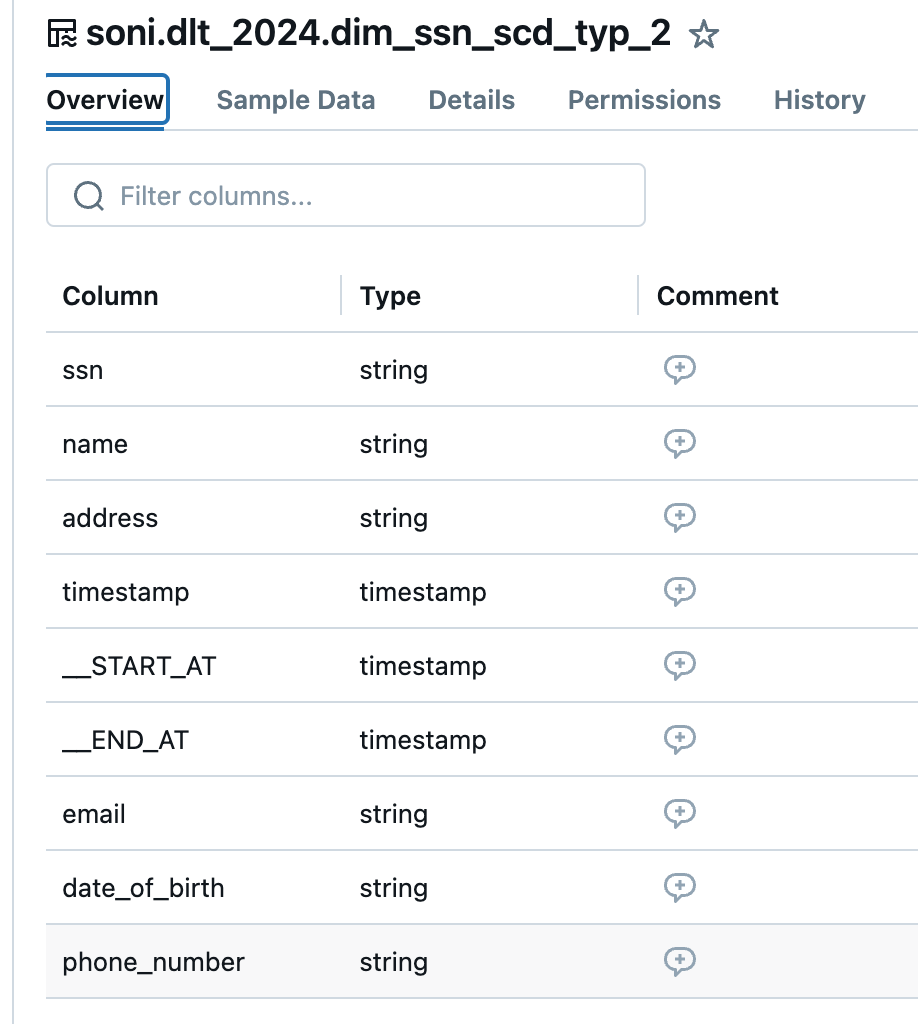
Explanation
- Creating Views: The
create_viewfunction generates a streaming DataFrame for each table, reading data from the respective Delta table. - Streaming Table: The
create_streaming_tablefunction initializes the target Delta table with optimization properties. - Merging Data: The
apply_changesfunction merges data from each view into the target table, ensuring data consistency and handling Slowly Changing Dimensions (SCD) efficiently.
Usage Notes
- Concurrency: Only one
APPLY CHANGESflow for each target table can run concurrently. - Consistency: All
APPLY CHANGESflows targeting a table must have the same keys, sequencing, and TRACK HISTORY columns. - Preview Channel: This feature is currently available in the preview channel of Delta Live Tables.
How to stream out of this target table
With DBR 15.3, one can read the change feed outside of DLT and then stream changes for futher processing.
display(
spark.readStream.format("delta")
.option("readChangeFeed", "true").table("soni.dlt_2024.dim_ssn_scd_typ_2")
)
Conclusion
Delta Live Tables provides a powerful and flexible way to merge multiple data streams into a single Delta table. By leveraging DLT’s capabilities, data engineers can ensure real-time data consistency and handle complex data integration tasks with ease.
Start using Delta Live Tables today to streamline your data processing pipelines and ensure your data is always up-to-date. Go Build!!!
Footnote:
Thank you for taking the time to read this article. If you found it helpful or enjoyable, please consider clapping to show appreciation and help others discover it. Don’t forget to follow me for more insightful content, and visit my website CanadianDataGuy.com for additional resources and information. Your support and feedback are essential to me, and I appreciate your engagement with my work.
Note: All opinions are my own.