 Skip to content
Skip to content 
- All Posts
- Best Practices
- Blog
- Databricks
- Delta
- Delta Live Tables
- forEachBatch
- kafka
- Spark
- Stream
- Stream-Stream
- Streaming Aggregation

Ready to conquer your data interviews and land that dream job? Here’s a powerful guide packed with actionable steps to…

Introduction In today’s data landscape, organizations often deal with multiple input datasets from various sources like Kafka, Kinesis, and Delta…
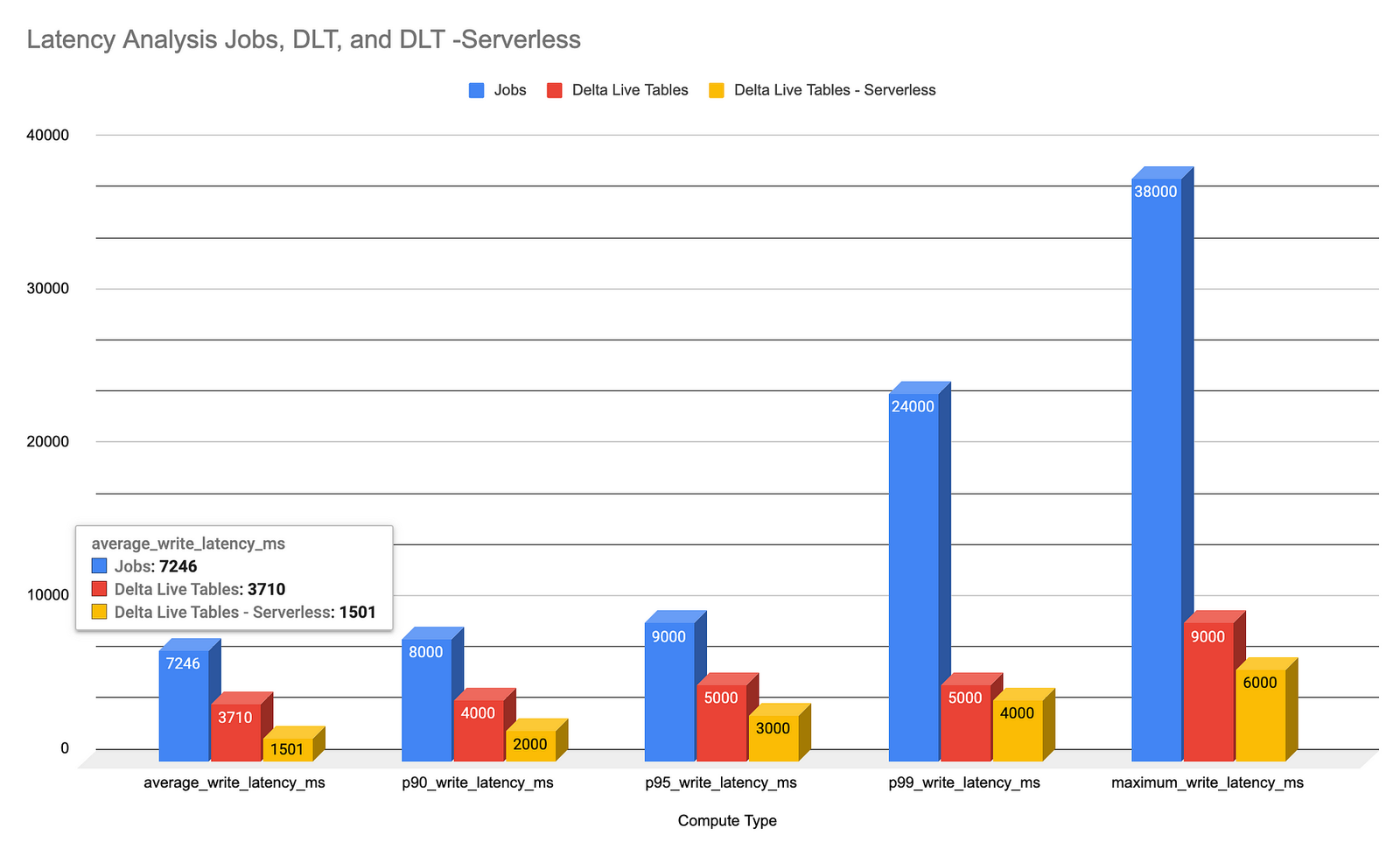
Introduction Welcome back to the second installment of our series on data ingestion from Kafka to Delta tables on the…

Introduction In the fast-paced world of data engineering, there often arises a need to generate large volumes of synthetic data…

This blog will discuss how to read from a Spark Streaming and merge/upsert data into a Delta Lake. We will…

Introduction: In the realm of big data processing, where efficiency and speed are paramount, Apache Spark shines as a potent…
