 Skip to content
Skip to content 

This blog will discuss passing custom parameters to a Delta Live Tables (DLT) pipeline. Furthermore, we will discuss importing functions defined in other files or locations. You can import files from the current directory or a specified location using sys.path.append().
Update: As of December 2022, you can directly import files if the reusable_functions.py file exists in the same repository by just using the import command, which is the preferred approach. However, in case these reusable_functions.py file exists outside the repository, you can take the sys.path.append() approach mentioned below.
Overall, this a 4-step process:
- Create a reusable_functions.py file
- Add code to receive the DLT parameters
- Append the path to reusable_functions.py file and import the functions in the notebook
- Create a DLT pipeline and set/pass parameters
1. Create a reusable_functions.py file
Create a reusable function in a Python File (not Notebook), so we can import it later. Let’s call the file ‘reusable_functions.py’ below and place it in a path. Please make sure to note the absolute path of the folder where this file will be placed.
from pyspark.sql import DataFrame
from pyspark.sql.functions import current_timestamp, current_date
def append_ingestion_columns(_df: DataFrame):
return _df.withColumn("ingestion_timestamp", current_timestamp()).withColumn(
"ingestion_date", current_date()
)
2. Add code to receive the DLT parameters
The below function is defined with try and except block so that it can work with Notebook as well, where we cannot pass the parameter value from the DLT pipeline
from pyspark.sql import SparkSession
def get_parameter_or_return_default(
parameter_name: str = "pipeline.parameter_blah_blah",
default_value: str = "default_value",
) -> str:
try:
spark = SparkSession.getActiveSession()
if spark is not None:
parameter = spark.conf.get(parameter_name)
else:
raise Exception("No active Spark session found.")
except Exception as e:
print(f"Caught Exception: {e}. Using default value for {parameter_name}")
parameter = default_value
return parameter
In this example, we will pass two parameters: path_to_reusable_functions & parameter_abc. Then we will use the function defined previously to get and set default values for both.
path_to_reusable_functions = get_parameter_or_return_default(
parameter_name="pipeline.path_to_reusable_functions",
default_value="/Workspace/Repos/jitesh.soni@databricks.com/material_for_public_consumption/",
)
parameter_abc = get_parameter_or_return_default(
parameter_name="pipeline.parameter_abc", default_value="random_default_value"
)
3. Append the path to reusable_functions.py file and import the functions in the notebook
import sys
# Add the path so functions could be imported
sys.path.append(path_to_reusable_functions)
# Attempt the import
from reusable_functions import append_ingestion_columns
Next step, we will define a function to return a DataFrame and the run display command to see the output of the function. This helps one test if the code works without running the DLT pipeline.
def static_dataframe():
df_which_we_got_back_after_running_sql = spark.sql(
f"""
SELECT
'{path_to_reusable_functions}' as path_to_reusable_functions
,'{parameter_abc}' as parameter_abc
"""
)
return append_ingestion_columns(df_which_we_got_back_after_running_sql)
display(static_dataframe())
At this point, you should be able to run your notebook and validate everything works before we create a DLT pipeline.
Next step, we define a DLT table.
import dlt
@dlt.table(name="static_table", comment="Static table")
def dlt_static_table():
return static_dataframe()
4. Create a DLT pipeline and set/pass parameters
At this step, we can create a DLT pipeline via UI, add our custom parameters, and assign them values.

The full JSON representation would look something like this, we only care about the configuration section in this JSON.
{
"id": "d40fa97a-5b5e-4fe7-9760-b67d78a724a1",
"clusters": [
{
"label": "default",
"policy_id": "E06216CAA0000360",
"autoscale": {
"min_workers": 1,
"max_workers": 2,
"mode": "ENHANCED"
}
},
{
"label": "maintenance",
"policy_id": "E06216CAA0000360"
}
],
"development": true,
"continuous": false,
"channel": "PREVIEW",
"edition": "CORE",
"photon": false,
"libraries": [
{
"notebook": {
"path": "/Repos/jitesh.soni@databricks.com/material_for_public_consumption/notebooks/how_to_parameterize_delta_live_tables_and_import_reusable_functions"
}
}
],
"name": "how_to_parameterize_delta_live_tables_and_import_reusable_functions",
"storage": "dbfs:/pipelines/d40fa97a-5b5e-4fe7-9760-b67d78a724a1",
"configuration": {
"pipeline.parameter_abc": "this_was_passed_from_dlt_config",
"pipeline.path_to_reusable_functions": "/Workspace/Repos/jitesh.soni@databricks.com/material_for_public_consumption/"
},
"target": "tmp_taget_schema"
} Trigger your DLT pipeline.
If you have reached so far, you should have an end-to-end DLT pipeline working with parameter passing and imports.
*Update | How do you edit these parameters via API or CLI
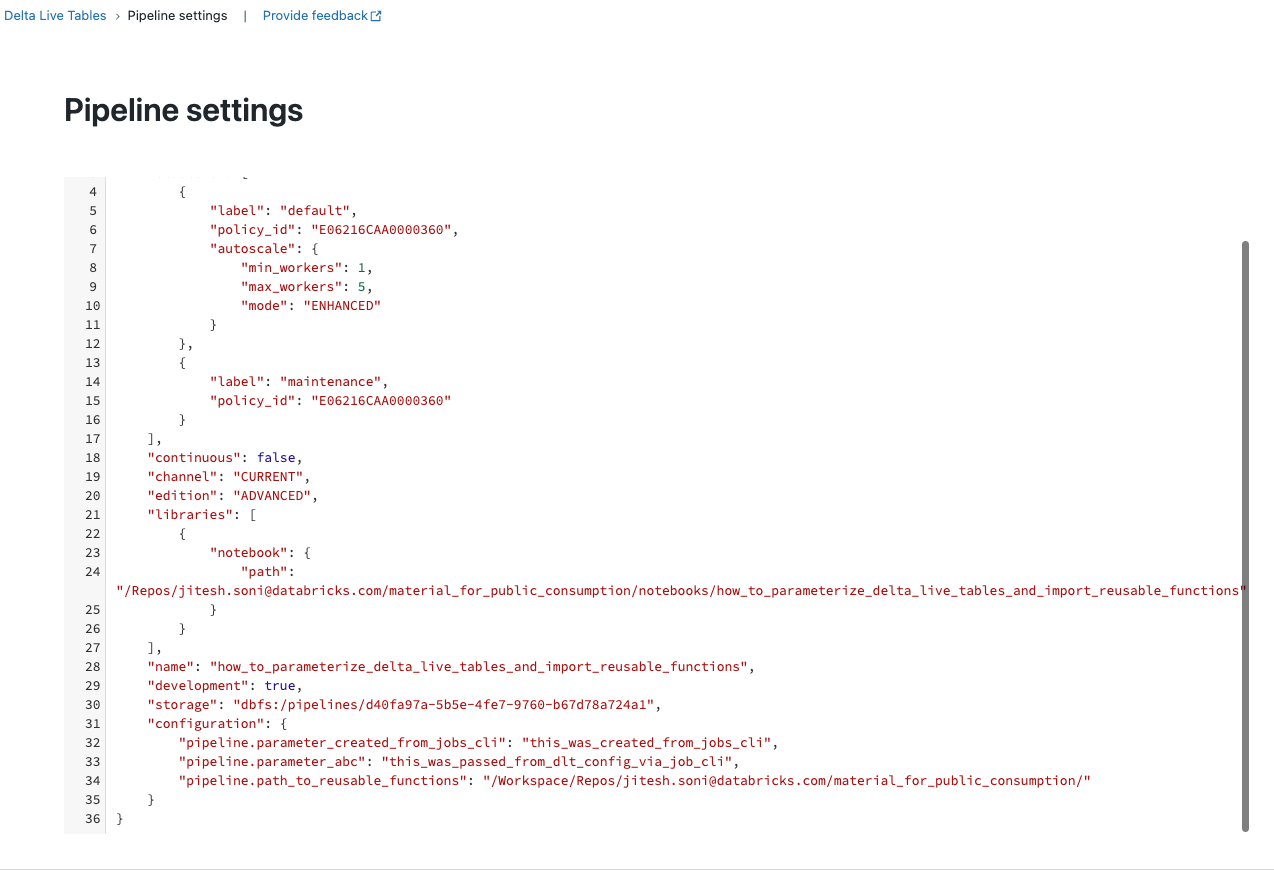
Below are screenshots of how to edit these parameters via CLI. The API solution would be similar.
Create a JSON file with the parameters:
{
"id": "d40fa97a-5b5e-4fe7-9760-b67d78a724a1",
"name": "how_to_parameterize_delta_live_tables_and_import_reusable_functions",
"clusters": [
{
"label": "default",
"policy_id": "E06216CAA0000360",
"autoscale": {
"min_workers": 1,
"max_workers": 5,
"mode": "ENHANCED"
}
},
{
"label": "maintenance",
"policy_id": "E06216CAA0000360"
}
],
"configuration": {
"pipeline.parameter_created_from_jobs_cli": "this_was_created_from_jobs_cli",
"pipeline.parameter_abc": "this_was_passed_from_dlt_config_via_job_cli",
"pipeline.path_to_reusable_functions": "/Workspace/Repos/jitesh.soni@databricks.com/material_for_public_consumption/"
},
"libraries": [
{
"notebook": {
"path": "/Repos/jitesh.soni@databricks.com/material_for_public_consumption/notebooks/how_to_parameterize_delta_live_tables_and_import_reusable_functions"
}
}
]
} Call the Datarbricks CLI to push the changes:

Go back to Delta Live Tables UI and the change would have gone through
Download the code
DLT notebook and Reusable_function.py
Footnote:
Thank you for taking the time to read this article. If you found it helpful or enjoyable, please consider clapping to show appreciation and help others discover it. Don’t forget to follow me for more insightful content, and visit my website CanadianDataGuy.com for additional resources and information. Your support and feedback are essential to me, and I appreciate your engagement with my work.
