 Skip to content
Skip to content 
It’s crucial to monitor task parameter variables such as job_id, run_id, and start_time while running ELT jobs. These system-generated values can be saved or printed for future reference. Please refer below to find the comprehensive list of supported parameters.

This is a simple 2-step process:
- Pass the parameter when defining the job/task
- Get/Fetch and print the values
Step 1: Pass the parameters
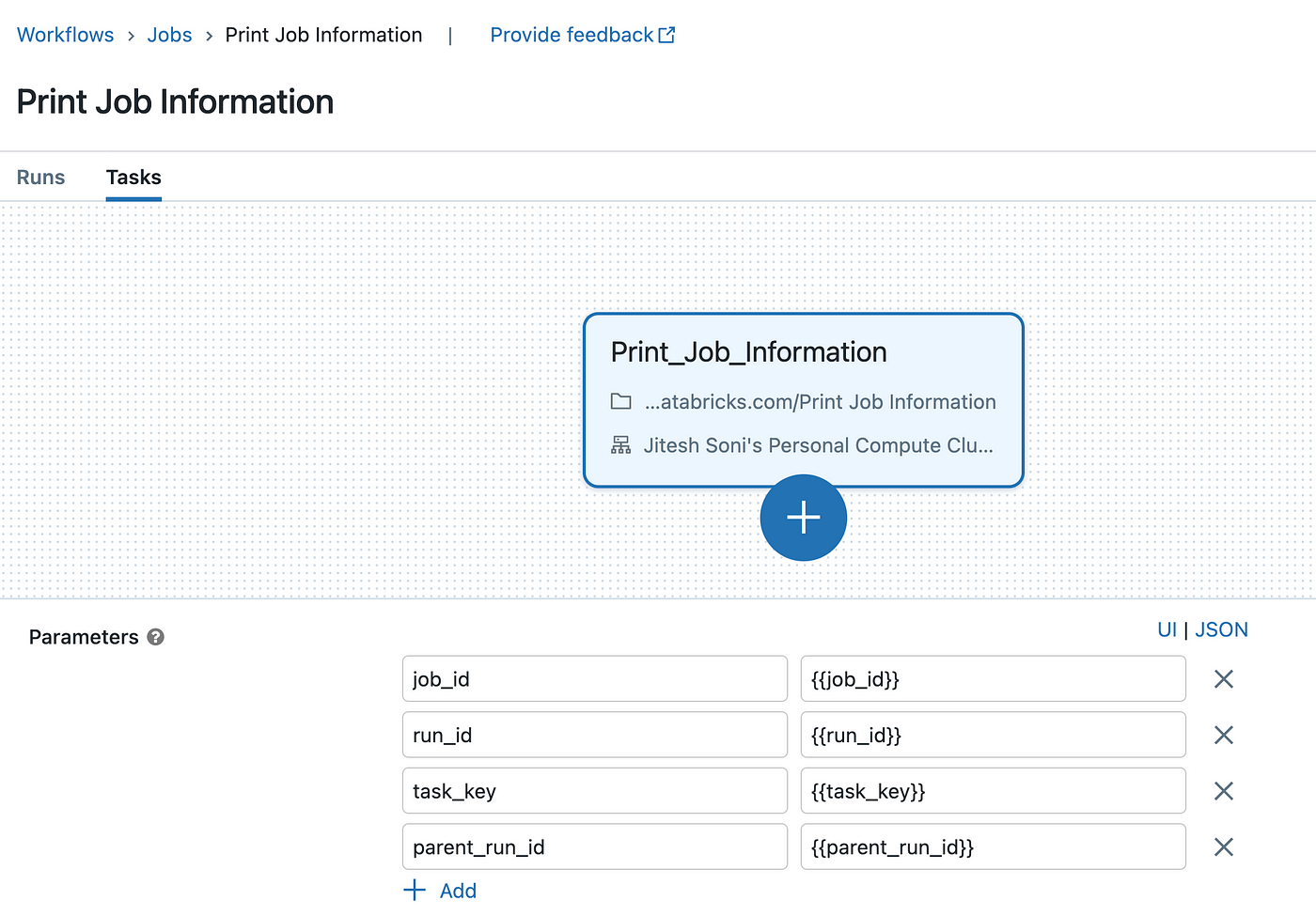
Step 2: Get/Fetch and print the values
print(f"""
job_id: {dbutils.widgets.get('job_id')}
run_id: {dbutils.widgets.get('run_id')}
parent_run_id: {dbutils.widgets.get('parent_run_id')}
task_key: {dbutils.widgets.get('task_key')}
""")
Next step, when you run the job; you should see an output like this

Advanced & quicker method to implement
Add the following boilerplate code on top of the notebook. It will capture whole context information instead, and you can parse whatever information is helpful to you.
The below is code based and attributes are subject to change without notice
import json, pprint
dict_job_run_metadata = json.loads(dbutils.notebook.entry_point.getDbutils().notebook().getContext().toJson())
print(f'''
currentRunId: {dict_job_run_metadata['currentRunId']}
jobGroup: {dict_job_run_metadata['jobGroup']}
''')
# Pretty print the dictionary
pprint.pprint(dict_job_run_metadata)
Footnote
Thank you for taking the time to read this article. If you found it helpful or enjoyable, please clapping to show appreciation and help others discover it. Don’t forget to follow me for more insightful content, and visit my website CanadianDataGuy.com for additional resources and information. Your support and feedback are essential to me, and I appreciate your engagement with my work.
