



Spark Join Strategies Explained: Broadcast Hash Join
Everything You Need to Know About Broadcast Hash Join

Apache Spark employs multiple join strategies to efficiently combine datasets in a distributed environment. This guide provides a zero-to-hero explanation of the three primary join strategies – Broadcast Hash Join (BHJ), Shuffle Hash Join (SHJ), and Sort-Merge Join (SMJ) – with a focus on Databricks. We will explore how each strategy works, their execution plans (DAG stages, partitioning, memory and shuffle behavior), and how to tune these joins on Databricks (including relevant configurations like AQE and join hints). A visual cheat sheet and further reading resources are provided at the end.
Introduction to Spark Join Strategies
In Spark SQL, a join combines two datasets by matching rows on a common key. The way Spark executes the join greatly impacts performance, especially with large data. Spark’s Catalyst optimizer will choose a join strategy based on data statistics (size of each side, join type, etc.), or you can influence it via hints and settings. The three main join strategies for equi-joins are:
Broadcast Hash Join (BHJ) – Broadcasts the entire smaller dataset to all executors, avoiding shuffles for that side, Very fast when one side is sufficiently small, analogous to a map-side join in Hadoop
Shuffle Hash Join (SHJ) – Shuffles both datasets on the join key, then builds a hash table on the smaller side of each partition and streams the larger side to find matches.
Avoids the sort step of SMJ but requires enough memory per partition.
Sort-Merge Join (SMJ) – Shuffles both datasets on the join key and sorts them, then merges sorted partitions to find matches. This is Spark’s default strategy for large data and supports all join types . It’s robust (can spill to disk if needed) but involves heavy network and CPU overhead for sorting.
Each strategy has optimal use cases and pitfalls. In Databricks (which uses Spark under the hood), adaptive query execution (AQE) can dynamically optimize joins (e.g. switching strategies or handling skew) to improve performance. We’ll now dive into each strategy in detail.
What is a Broadcast Hash Join (BHJ)?
A Broadcast Hash Join is an efficient strategy used to join two datasets in Spark when one of them is significantly smaller than the other. Instead of moving data across the network (shuffling) for both sides of the join, Spark copies—or "broadcasts"—the entire small dataset to every worker node (executor). Then, each executor performs a local hash join between its partition of the larger dataset and the entire, locally cached, small dataset. This approach helps to avoid expensive network shuffling and the need for sorting on either side of the join.
The Broadcast Process in Detail
The broadcast procedure involves:
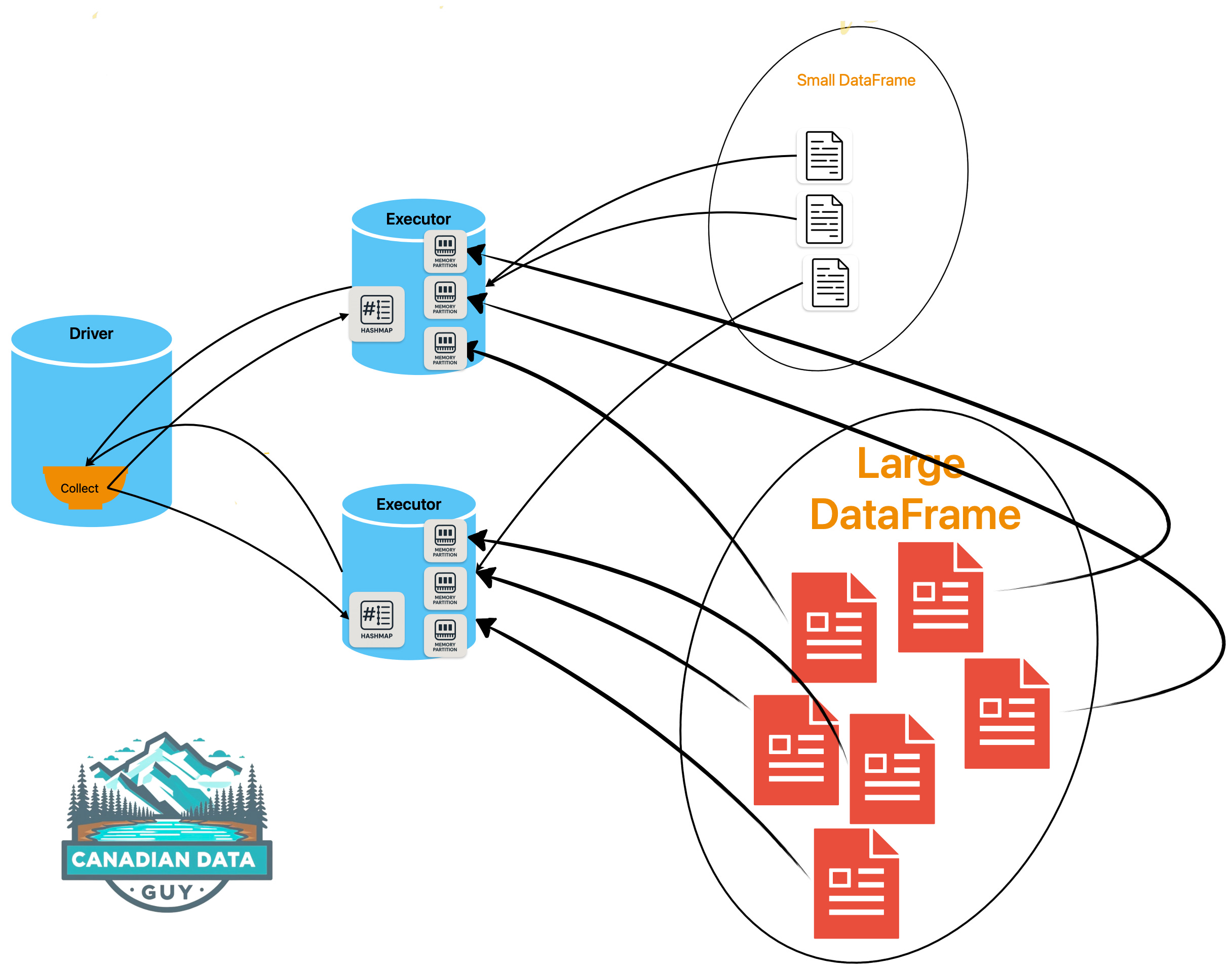
Collecting the Data:
The driver first gathers the entire small dataset and converts it into an efficient in-memory data structure (typically a hash map).
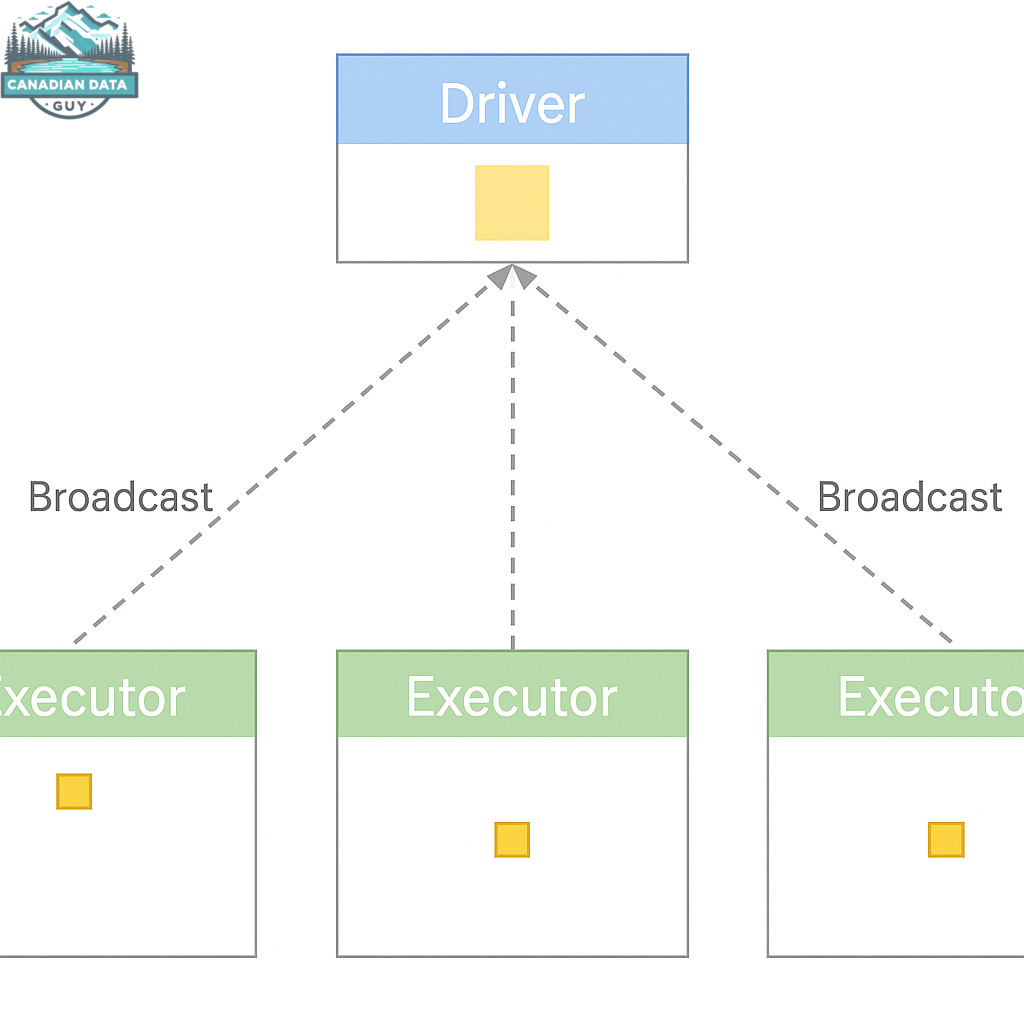
Distributing the Data:
This hash map is then distributed (broadcast) to all executor nodes, usually via a network distribution algorithm akin to torrent distribution.Utilizing the Broadcast Data:
Each executor then uses the broadcasted data to quickly look up matching join keys when processing its partition of the larger dataset.
Understanding these steps is crucial because if any stage fails—whether due to memory limits on the driver, executor constraints, or even network issues—the entire query may fail.
When Does Spark Use BHJ?
Spark will automatically choose to perform a Broadcast Hash Join under these conditions:
Dataset Size: One side of the join is smaller than a pre-configured threshold, which is by default 10 MB in open-source Spark. In Databricks environments, this threshold is commonly increased (e.g., ~30 MB with adaptive execution), meaning Databricks can handle moderately larger tables.
Join Type: The join condition is an equality condition (equi-join).
The setting spark.sql.autoBroadcastJoinThreshold controls this threshold and can be adjusted based on available memory and expected performance benefits.
BHJ works well with these join types:
Supported: Inner joins, and left, semi, or anti joins (as long as the correct side is broadcast).
Limitations: It is not supported for full outer joins. For right outer joins, only the left table can be broadcast; similarly, in left joins only the right table can be broadcast.
If the join type is not supported by a BHJ, Spark may revert to another join strategy, such as a sort-merge join or a broadcast nested loop join when dealing with non-equi conditions.
Databricks and Adaptive Query Execution (AQE)
In Databricks:
Adaptive Query Execution (AQE): AQE can dynamically convert a sort-merge join into a broadcast hash join if it determines at runtime that one side of the join is smaller than the broadcast threshold.
Higher Thresholds: Databricks’ default setting for auto-broadcast (often
spark.databricks.adaptive.autoBroadcastJoinThreshold) may be set higher (e.g., 30 MB) to allow for broadcasting moderately larger tables.Forcing Broadcasts: Although AQE works automatically, you might sometimes use explicit hints (such as
/*+ BROADCAST(table) */in SQL or wrapping a DataFrame withbroadcast(df)in PySpark) to ensure the small dataset is broadcast immediately, thereby skipping unnecessary shuffles.
Common Misconception- Order of Joins
For optimal join order performance: Perform joins from smallest to largest tables first to minimize data shuffling However, do broadcast joins last, even though this seems counterintuitive. This is because:
Broadcast joins don't require shuffles and can be executed efficiently even on large fact tables
If broadcast joins are done first, the joined data needs to be shuffled again for later joins
By doing broadcast joins last, we avoid having to shuffle that data again.
Group together joins that share the same ON clause to reduce shuffling, since the data is already arranged properly
Memory and Shuffle Considerations
Using BHJ provides tremendous speedups by eliminating the costly shuffle of the larger dataset. However, it comes with some significant memory considerations:
Driver Memory: The whole small dataset must be collected on the driver before it can be broadcast. The driver has a memory limit, defined by
spark.driver.maxResultSize, and exceeding this limit will cause the job to fail.Executor Memory: Each executor must have enough memory to store the broadcasted dataset along with its own processing workload. The available memory on the node with the smallest capacity is the practical limit.
Timeout and Overload Risks: If the dataset is even moderately large, broadcasting it might overwhelm the driver or network, leading to out-of-memory (OOM) errors or timeouts. For example, while Databricks has even seen broadcasts for datasets up to a few GB in size, one must exercise extreme caution when attempting such operations.
Compression Differences: Note that the on-disk size of data (like Parquet files in Delta tables) might be much smaller than the in-memory representation. Spark’s decisions are based on disk size, so actual in-memory data after decompression might far exceed the expected limits.
To address these issues, you can either disable auto-broadcast by setting spark.sql.autoBroadcastJoinThreshold to -1 or lower the threshold to ensure no large table is inadvertently broadcasted. On Databricks with the Photon engine, executor-side broadcasts further alleviate pressure on the driver because the broadcast process does not rely solely on the driver's resources.
Performance Recommendations
When to Use BHJ:
Use Broadcast Hash Join when one dataset is much smaller than the other. This is commonly the case when joining large fact tables with much smaller dimension tables or when one table is the result of a selective filter.Why Forcing Broadcasts:
While Spark’s optimizer may choose to broadcast small datasets automatically, in complex queries or skewed datasets the statistics might not be accurate. In those cases, manually forcing a broadcast using explicit hints ensures that the join operation skips the shuffle stage and executes as a broadcast join.Caution in Production:
Forcing broadcasts in ad hoc queries or development is acceptable. However, in production workloads, it’s important to validate the dataset size at runtime. This can be done by checking record counts and partition sizes to avoid overloading any executor or the driver. Monitoring the Spark UI is critical to ensure broadcasts do not result in GC (garbage collection) pressure or other resource issues.
Example SQL with Broadcast Hint
To explicitly force a broadcast in SQL, you can include the following hint in your query:
SELECT /*+ BROADCASTJOIN(table1)*/ table1.id, table1.col, table2.id, table2.int_col FROM table1 JOIN table2 ON table1.id = table2.id;In the physical plan, you will see a BroadcastExchange operator for the small table along with a BroadcastHashJoin operator, indicating that the join was executed without additional shuffling of the large table.
SQL Query :
select /*+ BROADCASTJOIN(table1)*/ table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id
Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false\n
+- BroadcastHashJoin [id#271L], [id#286L], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#955]
: +- Filter isnotnull(id#271L)
: +- Scan ExistingRDD[id#271L,col#272]
+- Filter isnotnull(id#286L)
+- Scan ExistingRDD[id#286L,int_col#287L]
Number of records processed: 799541
Querytime : 15.35717314 secondsKey Pitfalls and Best Practices
Avoid Broadcasting Too Much Data:
Never broadcast a table that is too large (generally over 1GB) as it can overwhelm the driver and executors. Spark has a hard limit (roughly 8GB) on what it can broadcast.Watch for Non-Equi Joins:
BHJ only supports joins using equality conditions (equi-joins). When using non-equi join conditions (such as range conditions), BHJ cannot be applied.Force with Caution:
When you force a broadcast using hints or functions likebroadcast(df), you bypass Spark’s adaptive query execution optimizations. This is useful if you are sure the data size is small, but can cause performance issues if the dataset unexpectedly grows.Plan for Memory Needs:
Increase the broadcast thresholds only if your driver and executors have ample memory. For instance, a driver with 32GB+ memory might safely use higher thresholds (like 200MB). Be sure to also configurespark.driver.maxResultSizeappropriately to avoid driver-level memory errors.
Production Advice
When deploying BHJ in production workloads, careful planning and ongoing monitoring are essential to ensure stable performance:
Validate Data Sizes: Always verify that the dataset chosen for broadcasting is truly small both on disk and in-memory. Measure the record count and partition sizes before forcing a broadcast. This helps prevent unexpected OOM (out-of-memory) failures, which can occur when the dataset size exceeds available memory on the driver or executors.
Check Data Size and Record Count
Count the Records: Before attempting a broadcast, run a simple
df.count()on the small dataset. This confirms that the number of records is within an acceptable range.Estimate Data Size in Memory: Sometimes the dataset's on-disk size differs from its in-memory footprint. You can either use approximations from your data source’s statistics or compute a rough estimate using:
# Example in PySpark data_size_in_bytes = df.rdd.map(lambda row: len(str(row))).sum() print("Approximate in-memory size (bytes):", data_size_in_bytes)While this isn’t exact, it provides an estimate that can be compared against thresholds like
spark.sql.autoBroadcastJoinThreshold
Threshold Validation before Forcing a Broadcast
Compare Against Broadcast Thresholds: Before performing an explicit broadcast, validate that the data size is below the configured threshold (e.g., 10MB, 30MB, or a custom value in your Spark configuration). This might involve:
broadcast_threshold = int(spark.conf.get("spark.sql.autoBroadcastJoinThreshold").replace("b", "")) # Assume approximate_size holds our computed or estimated size of the dataset in bytes. if approximate_size < int(broadcast_threshold): print("Proceed with broadcast") # Then use broadcast from pyspark.sql.functions import broadcast df_broadcasted = broadcast(df) else: print("Data too large; do not broadcast")This validation helps avoid unintentionally broadcasting a dataset that is too big, potentially causing an OOM error.
Monitor Resource Usage: Leverage Spark’s UI and logging mechanisms to track metrics like GC (garbage collection) activity, memory usage, and broadcast sizes. The smallest available executor memory sets the limit, so ensure that the broadcast data comfortably fits on each node.
Use Adaptive Query Execution (AQE) Carefully: While Spark’s AQE can convert joins to BHJ at runtime, explicitly broadcasting small datasets using hints or functions like
broadcast(df)can bypass the overhead of shuffling. However, avoid hardcoding broadcast hints unless you are confident of the dataset's size, as data volumes may fluctuate in production workloads.Configure Thresholds Cautiously: Adjust configurations such as
spark.sql.autoBroadcastJoinThreshold(and related thresholds in environments like Databricks) based on current cluster resources. For drivers with high memory (32GB+), thresholds can be increased, but setting these too high risks overwhelming your system if data volumes grow unexpectedly.Plan for Scalability and Edge Cases: Implement safeguards within your production pipelines. For instance, include runtime validations or logic to disable broadcasting dynamically when data sizes approach critical limits. This is especially important for pipelines handling dynamic or streaming data where bursts of data could otherwise lead to system instability.
If you’re running a driver with a lot of memory (32GB+), you can safely raise the broadcast thresholds to something like 200MB
set spark.sql.autoBroadcastJoinThreshold = 209715200;
set spark.databricks.adaptive.autoBroadcastJoinThreshold = 209715200;Why do we need to explicitly broadcast smaller tables if AQE can automatically broadcast smaller tables for us? The reason for this is that AQE optimizes queries while they are being executed.
Spark needs to shuffle the data on both sides and then only AQE can alter the physical plan based on the statistics of the shuffle stage and convert to broadcast join
Therefore, if you explicitly broadcast smaller tables using hints, it skips the shuffle altogether and your job will not need to wait for AQE’s intervention to optimize the plan
Never broadcast a table bigger than 1GB because broadcast happens via the driver and a 1GB+ table will either cause OOM on the driver or make the drive unresponsive due to large GC pauses
Please take note that the size of a table in disk and memory will never be the same. Delta tables are backed by Parquet files, which can have varying levels of compression depending on the data. And Spark might broadcast them based on their size in the disk — however, they might actually be really big (even more than 8GB) in memory after the decompression and conversion from column to row format. Spark has a hard limit of 8GB on the table size it can broadcast. As a result, your job may fail with an exception in this circumstance. In this case, the solution is to either disable broadcasting by setting
spark.sql.autoBroadcastJoinThresholdto -1 and do the explicit broadcast using hints (or the PySpark broadcast function) of the tables that are really small in the disk as well as in memory, or set thespark.sql.autoBroadcastJoinThresholdto smaller values like 100MB or 50MB instead of setting the threshold to -1.The driver can only collect up to 1GB of data in memory at any given time, and anything more than that will trigger an error in the driver, causing the job to fail. However, since we want to broadcast tables larger than 10MB, we risk running into this problem. This problem can be solved by increasing the value of the following driver configuration.
Please keep in mind that because this is a driver setting; it cannot be altered once the cluster is launched. Therefore, it should be set under the cluster’s advanced options as a Spark config. Setting this parameter to 8GB for a driver with >32GB memory seems to work fine in most circumstances. In certain cases where the broadcast hash join is going to broadcast a very large table, setting this value to 16GB would also make sense.
In Photon, we have the executor-side broadcast. So, you don’t have to change the following driver configuration if you use a Databricks Runtime (DBR) with Photon.
spark.driver.maxResultSize 16gFinal Thoughts
In summary, Broadcast Hash Join is a fast and efficient joining strategy in Spark for skewed or unbalanced joins where one dataset is significantly smaller. It avoids the expensive shuffling of the larger dataset by replicating the small data across all executors, enabling quick local hash lookups. However, its effectiveness depends heavily on the small dataset fitting in memory on the driver and executors. Forcing broadcasts should be done judiciously, with thorough validations in production to prevent resource exhaustion and associated failures.
By understanding the details of how BHJ operates and its configurations, you can better optimize your Spark jobs and manage performance, especially in environments like Databricks where adaptive query execution and executor-side optimizations further enhance its capabilities.
How the Process Works
BHJ operates in two main phases:
Broadcast Phase:
Collection and Broadcast: The small table is first collected by the Spark driver. After collection, the data is broadcast to all the executors across the cluster.
Local Caching: Once received on each node, the small dataset is cached in memory as a read-only broadcast variable. This ensures that the data is immediately available for the join process without any further data movement.
Hash Join Phase:
Building a Hash Map: Each executor creates an in-memory hash map from the broadcasted dataset. The hash map is built using the join key.
Local Join Operation: As the larger dataset is processed, every row in each partition is checked against the hash map for matching join keys. Because the small dataset is already available locally, this lookup is very fast and eliminates the need for shuffling data across the network.
Since no sort or extra merge steps are required, this one-pass in-memory lookup per partition makes the Broadcast Hash Join particularly quick, especially in common scenarios like joining large fact tables with much smaller dimension tables (a typical star schema pattern).
Further Reading
For more in-depth information and the latest updates on Spark join optimizations, the following resources are highly recommended:
Apache Spark Official Documentation – SQL Performance Tuning: Covers join strategy hints, adaptive execution, etc. (See “Join Strategy Hints” and “Adaptive Query Execution” in the Spark docs)
Tuning Spark SQL queries for AWS Glue and Amazon EMR Spark jobs
Apache Spark Official Documentation – Adaptive Query Execution (AQE): Detailed explanation of AQE features like converting SMJ to BHJ/SHJ and skew join handling
Databricks Documentation – Join Hints & Optimizations: Databricks-specific docs on join strategies, including the
SKEWandRANGEhints, and how AQE is used on Databricks“How Databricks Optimizes Spark SQL Joins” – Medium (dezimaldata): A blog post (Aug 2023) summarizing Databricks’ techniques like CBO, AQE, range join and skew join optimizations
“Top 5 Mistakes That Make Your Databricks Queries Slow” – Perficient Blog: Section 1 and 2 discuss data skew and suboptimal join strategies, with tips on salting and broadcast joins
Spark Summit Talks on Joins and AQE: Videos like “Optimizing Shuffle Heavy Workloads” or “AQE in Spark 3.0” (by Databricks engineers) for a deeper understanding of the internals of join execution and tuning.
https://spark.apache.org/docs/latest/sql-performance-tuning.html#join-strategy-hints
https://spark.apache.org/docs/latest/sql-performance-tuning.html#adaptive-query-execution
https://docs.databricks.com/en/sql/language-manual/hints.html
https://medium.com/@dezimaldata/how-databricks-optimizes-spark-sql-joins-aqe-cbo-and-more-5ac4c4d53091
https://www.perficient.com/insights/blog/2023/01/top-5-mistakes-that-make-your-databricks-queries-slow
https://www.databricks.com/resources/whitepapers/optimizing-apache-spark-on-databricks
By consulting these materials, you can deepen your understanding of Spark join mechanisms and keep up to date with the evolving best practices on the Databricks platform.

